Get the processed task mining data
Apromore performs computations internally to convert the raw data of events collected into a complete event log. At any point during or after a project, we can get this task mining event log. The list of processing done includes:
Merging of all raw data CSVs: Data from all four raw event CSV files (window events, element focus events, data items, and copy-paste events) is merged to enhance event attributes.
Cleaning the data: Some events may not have an ID based on the config rule specified. To ensure all events have a case ID, Apromore populates the null Case IDs with the Case ID value of the prior events or subsequent events.
Separating event logs by identifier: Apromore groups the event logs based on the identifier in the configuration. For instance, if events are identified as either Salesforce or GitHub in the configuration file, the final event log will be organized into two separate folders: the ‘Salesforce’ folder, containing only Salesforce events, and the ‘GitHub’ folder, containing only GitHub events.
We can collect this data in two forms:
Downloading the processed task mining data from the project page.
Creating an ETL pipeline to load the process data as an event log.
Download processed task mining data
To access the file from the task mining cockpit, go to the project and click Download processed data.
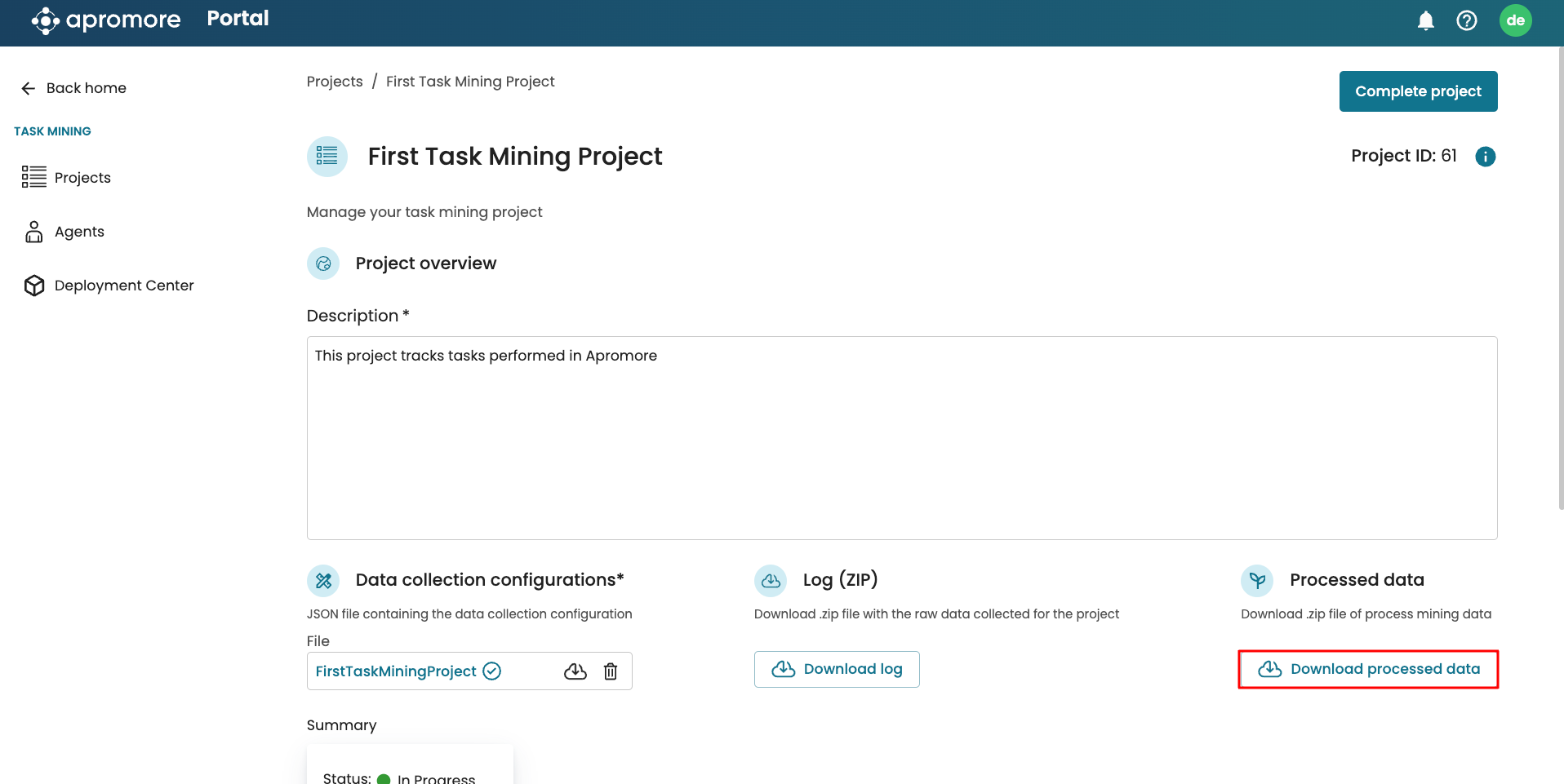
This downloads a ZIP file containing the processed task mining data for each identifier. This data can be uploaded in Apromore as an event log.
Load the processed task mining data as an event log
The processed task mining data can be accessed using an ETL pipeline. The logs are saved as parquet files in the dedicated S3 folder. We can create an ETL pipeline to append them as one single log.
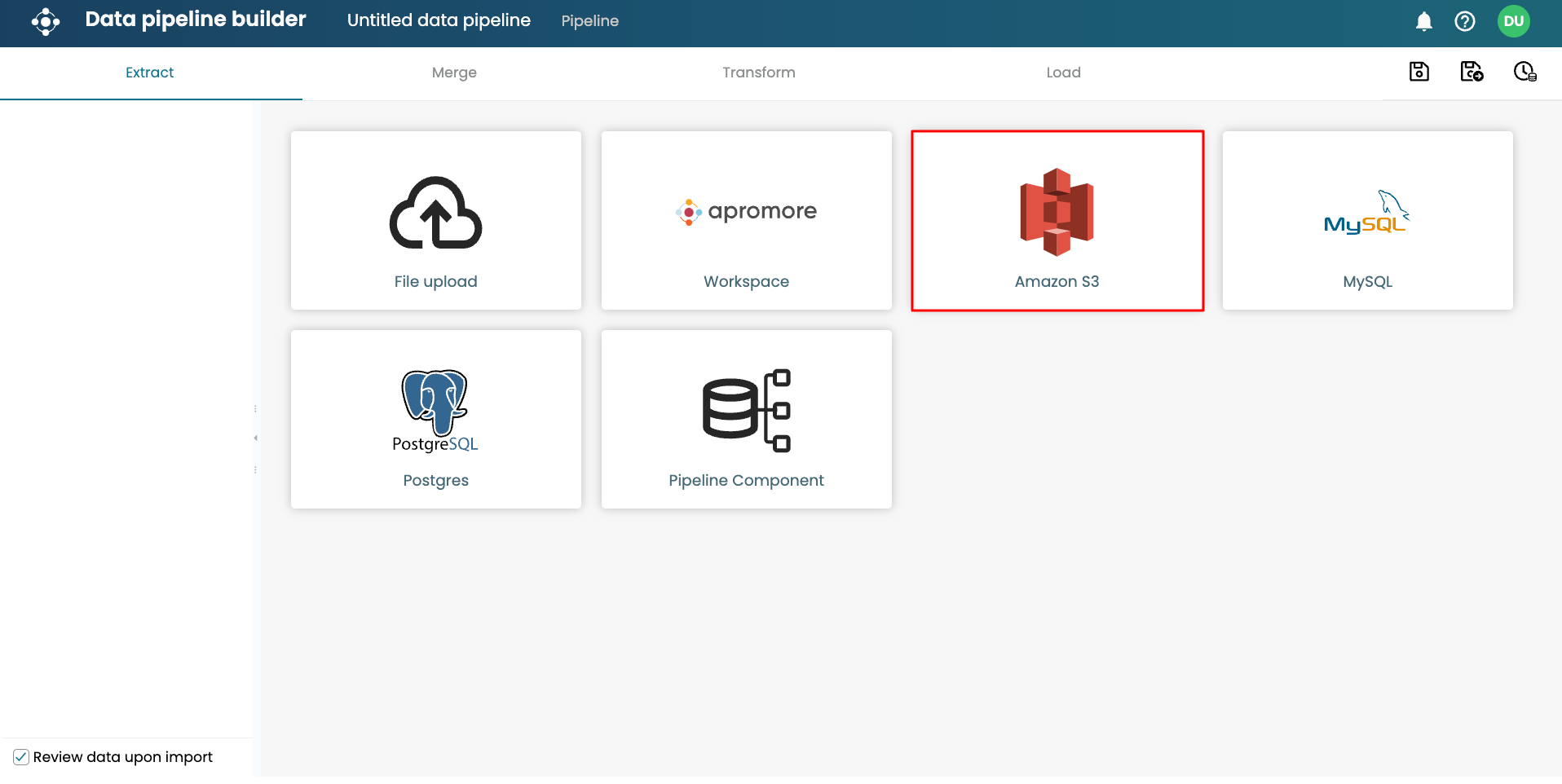
In the Extract phase of the ETL pipeline, select Amazon S3.
Click the folder icon to select the folder.
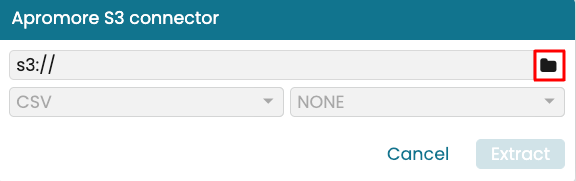
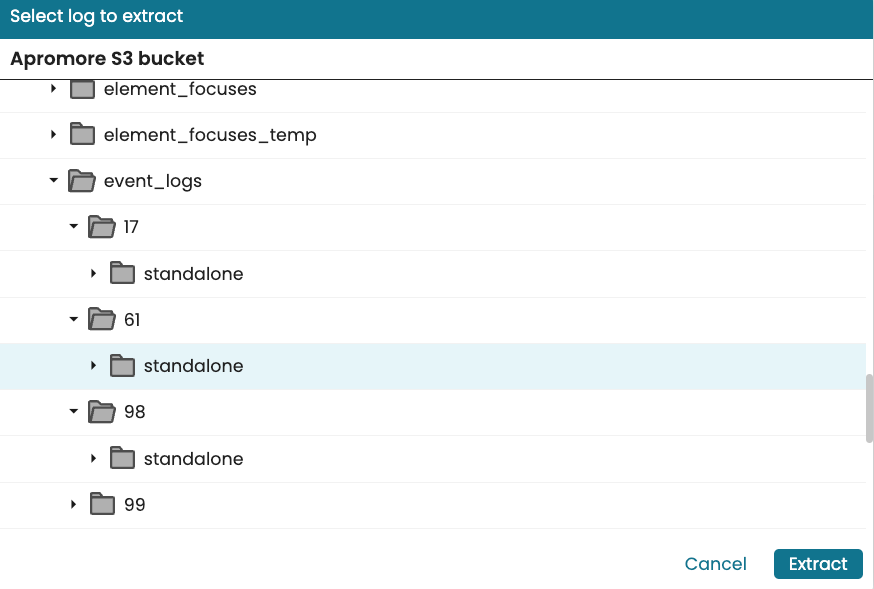
To ensure the pipeline always get new logs in the folder we use S3 microbatching. Go to the folder of the task mining project. This folder is in the path “taskmining > event_logs > {project_number} > standalone”.
Note
For every event tagged as an identifier in the configuration file, Apromore creates a different folder and stores its event log there. This is to ensure the extracted data are modular.
In the screenshot below, Project 61 had only Apromore events tagged as an identifier while Project 17 had Apromore, ExcelProcess, and StackOverflow tagged as identifiers.
Note
If the identifiers are interrelated and we wish to have all extracted data in an event log, we can create a new pipeline that merges the results of the individual processes.
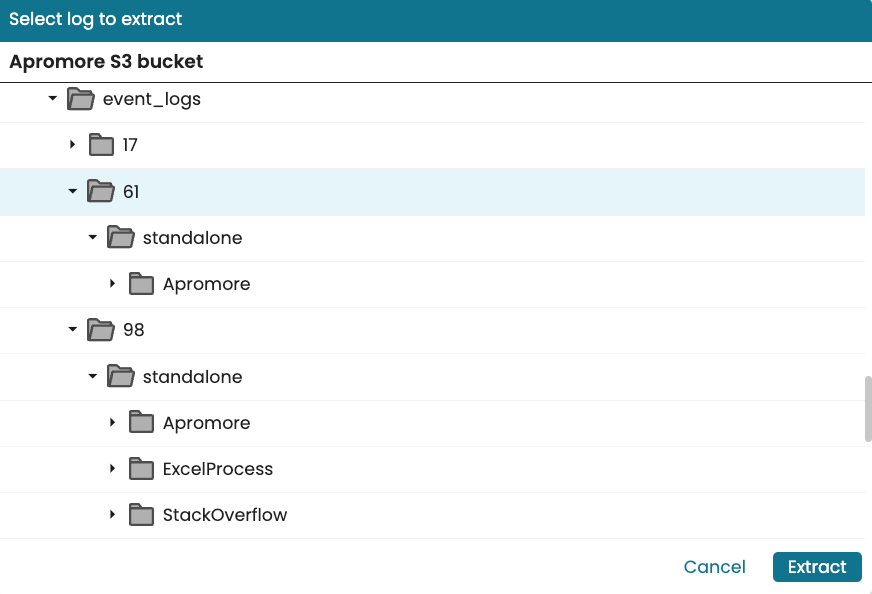
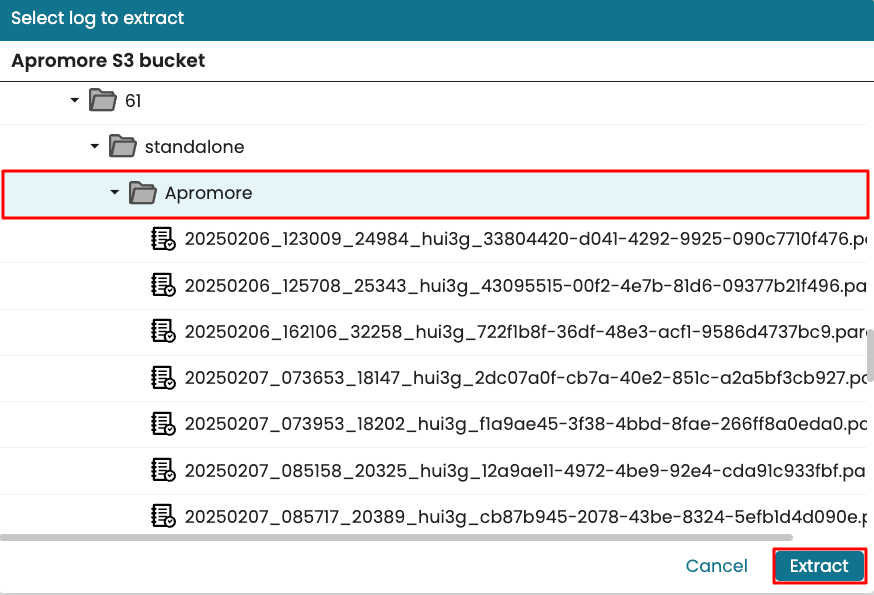
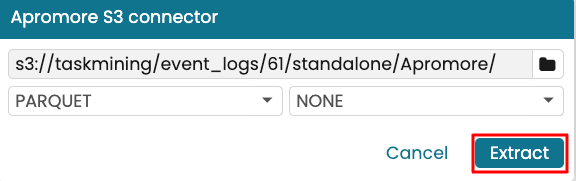
To extract the “Apromore” process task mining data for project 61, select Apromore and click Extract.
Change the file type to PARQUET.
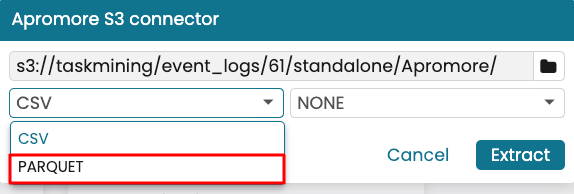
Once done, click Extract.
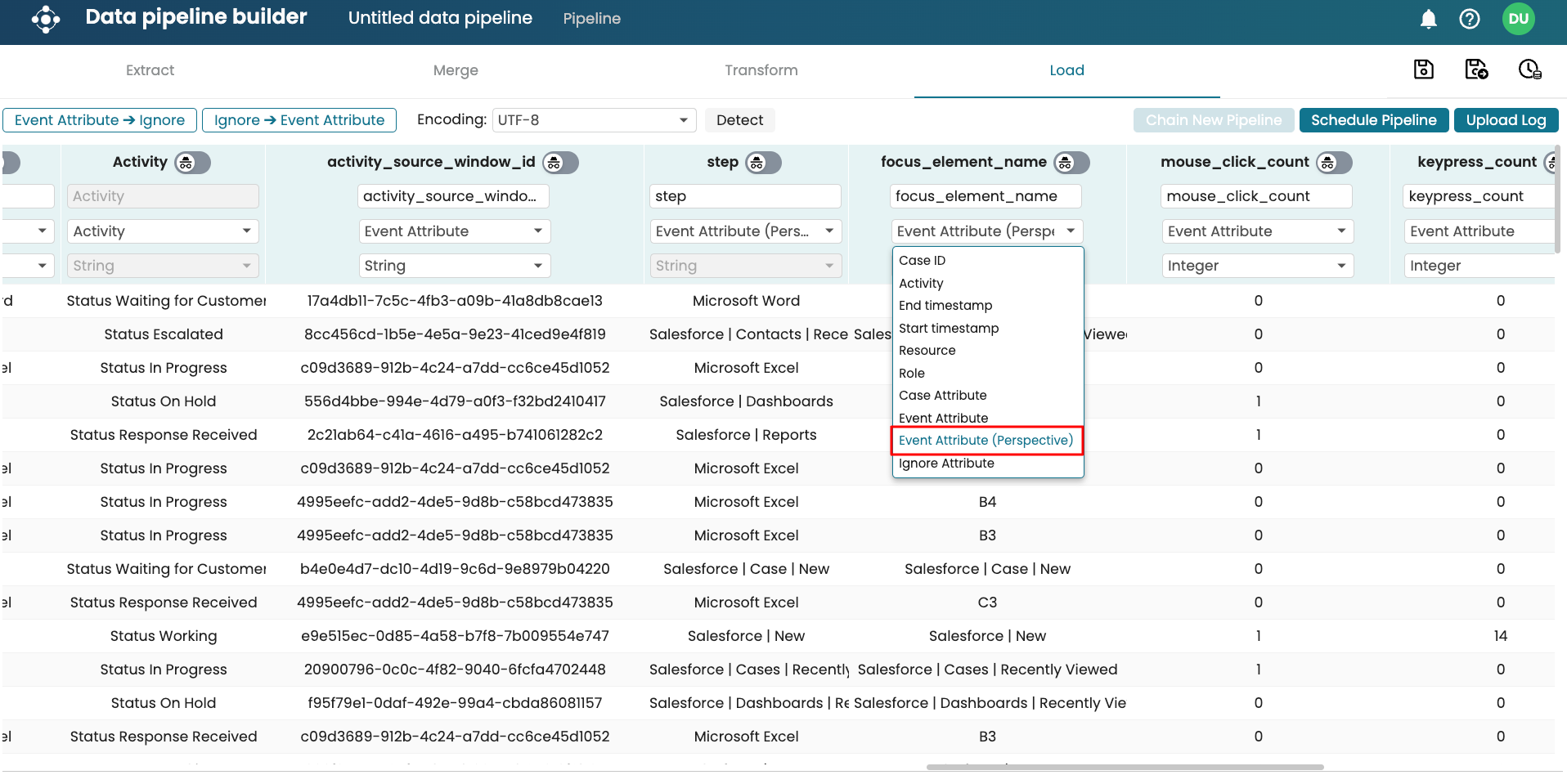
Apromore extracts the parquet files in the folder using S3 micro-batch ingestion. In the Load step, we should set the “step” and “focus element name” columns as Event Attributes (Perspective) so that we can drill down from the “Activity” level to the “Step” and “Focus element” level in Process Discoverer.
Click Schedule Pipeline to specify how frequently the pipeline will run.
Note
Since an S3 folder was selected at the Extract stage, after each pipeline run, Apromore automatically updates the log with any new files arriving in the folder.
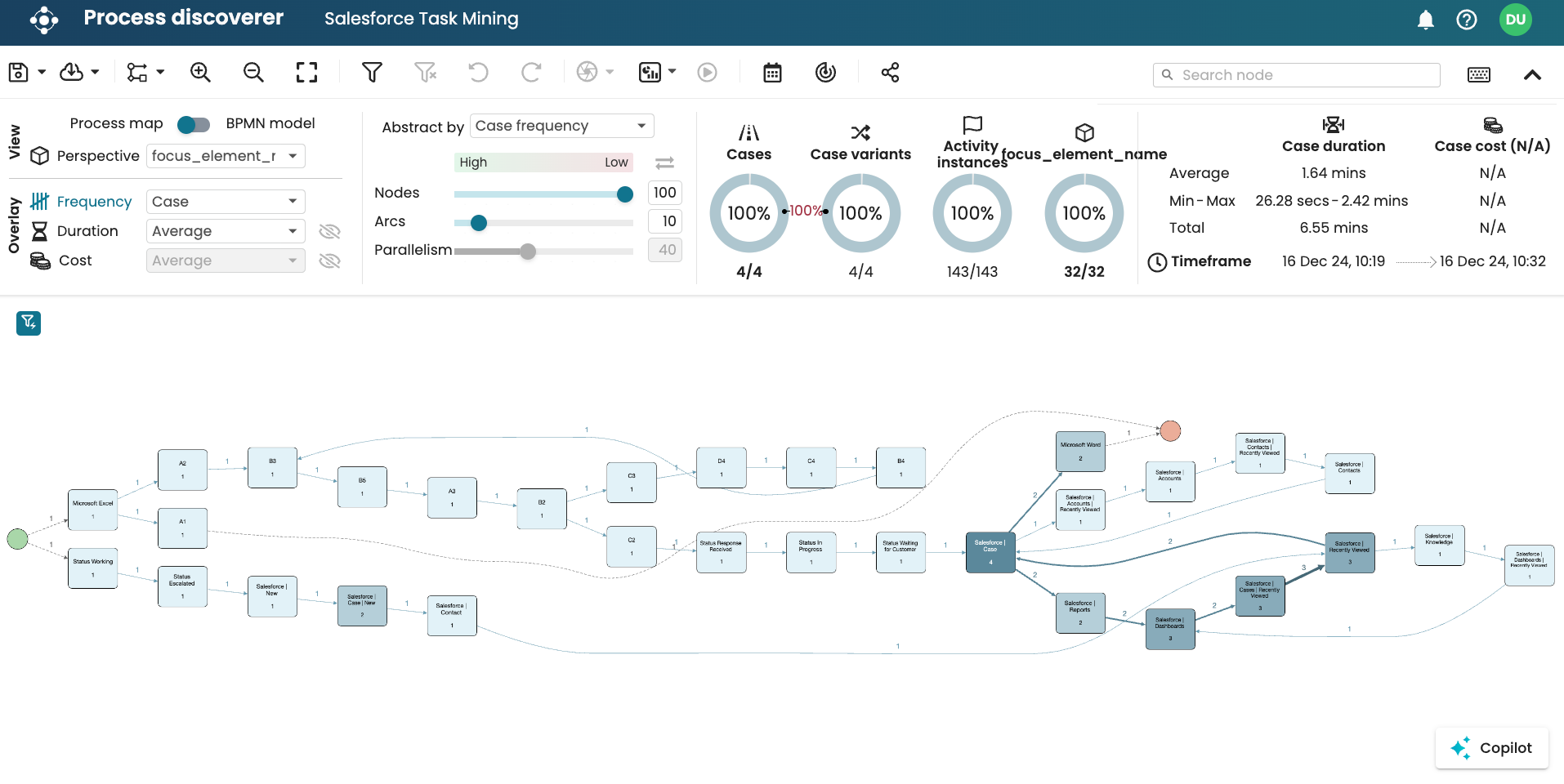
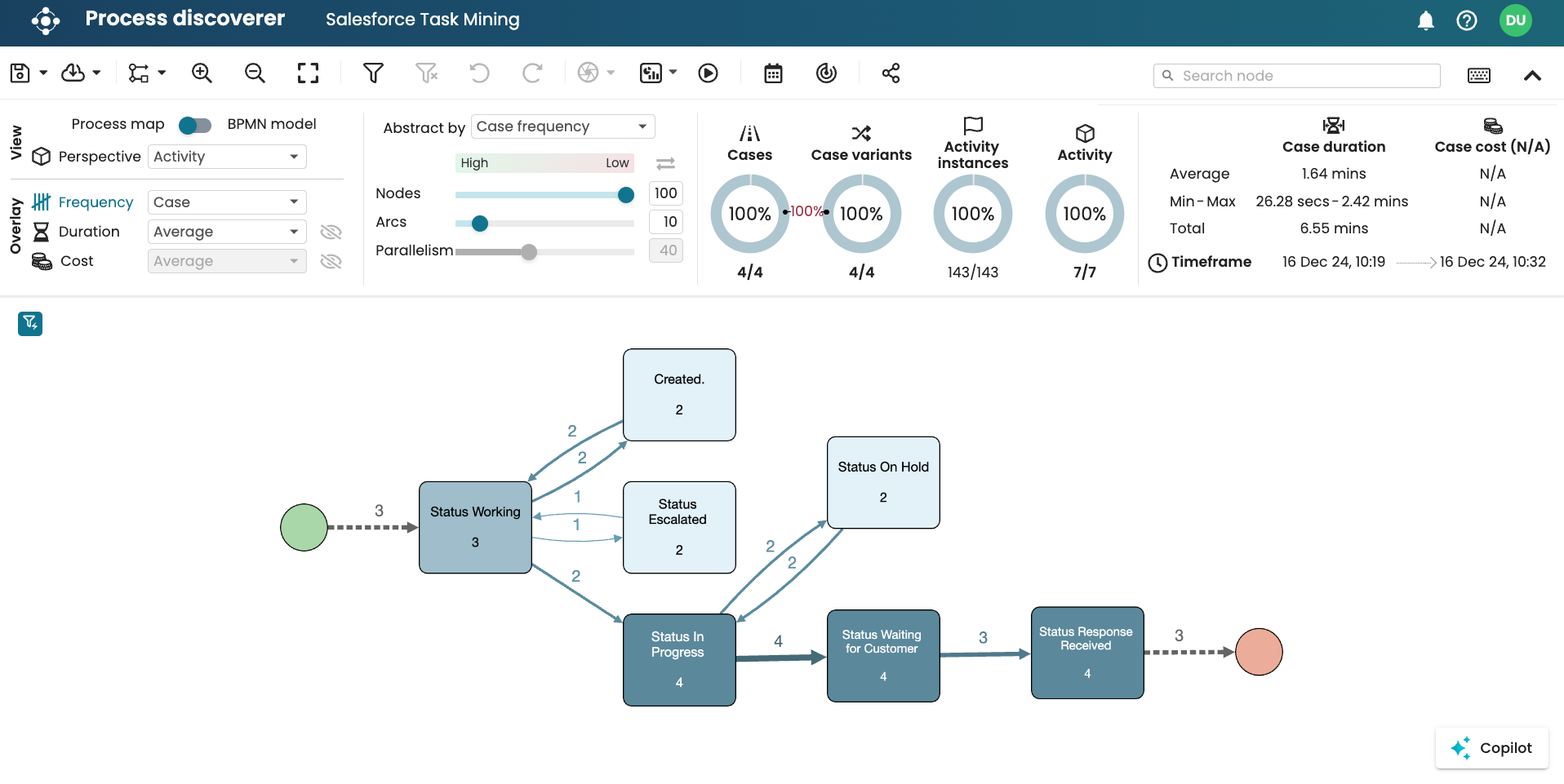
This is a sample task mining data in Apromore showing the different levels.
At the activity level:
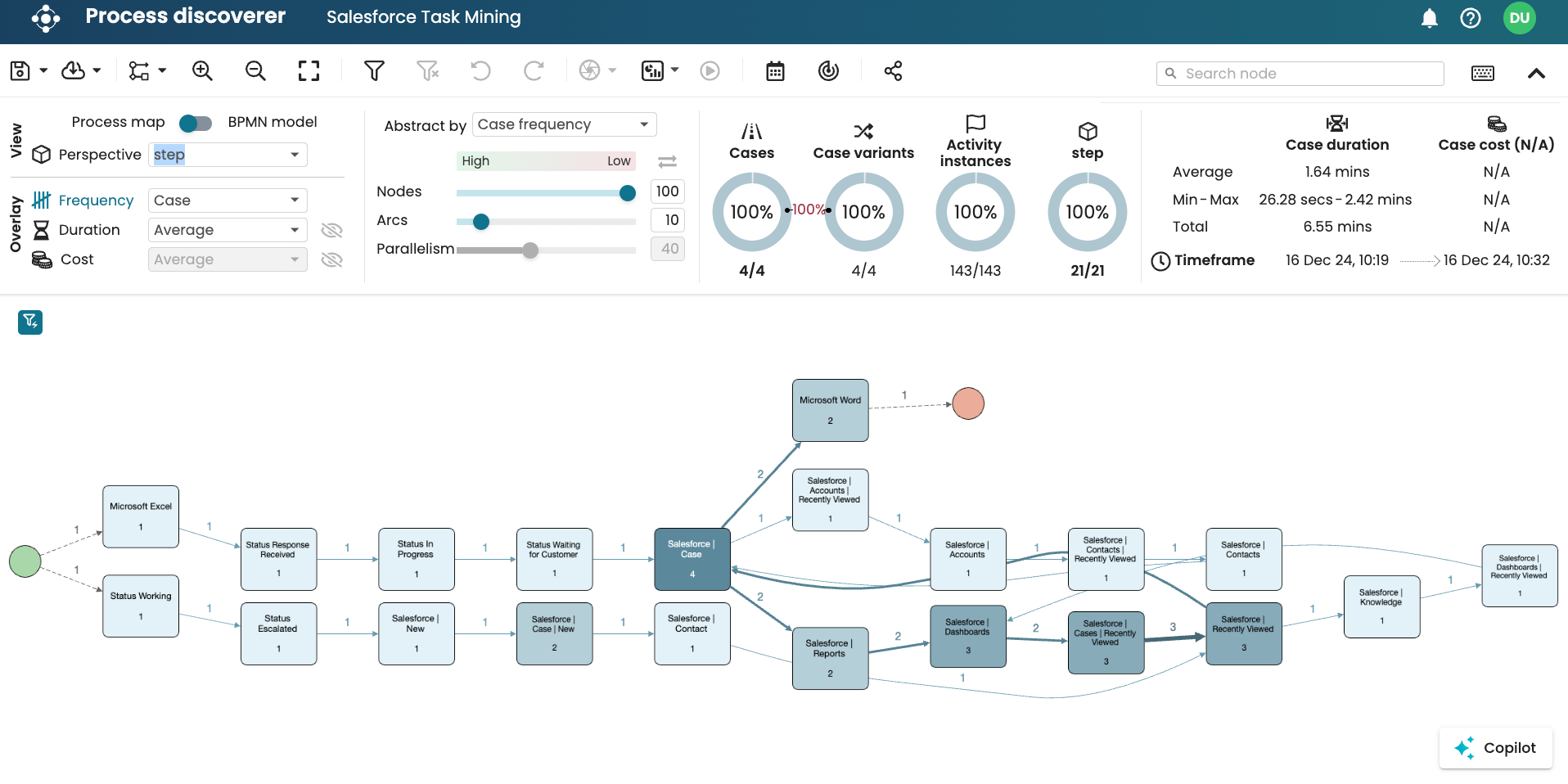
At the step level:
At the focus element level: